Les œuvres textuelles générées par intelligence artificielle au sein d’une condition hyperconnectée
Tom Lebrun,
« Les œuvres textuelles générées par intelligence artificielle
au sein d’une condition hyperconnectée »,
dans
jake moore,
Christelle Proulx (dir.),
L’agir en condition
hyperconnectée (édition augmentée), Presses de l’Université de
Montréal, Montréal, 2020, ISBN : 978-2-7606-4297-3, https://www.parcoursnumeriques-pum.ca/11-agir/chapitre3.html.
version 0, 22/9/2020
Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA
4.0)
En tant que nouvel agent actif et puissant, que fait l’intelligence artificielle aux productions culturelles actuelles ? La production littéraire numérique se transforme aussi de l’intérieur lorsqu’entre en scène la génération computationnelle. Ce chapitre explore le rôle de ces procédures en examinant les œuvres générées par du code dans le cadre du concours NaNoGenMo. Cette analyse permet de décrire la diversité des agents créatifs au travail dans l’élaboration d’un roman et le type d’intertextualité machinique produit à la suite de l’entraînement des algorithmes sur des œuvres littéraires préexistantes choisies. Il est ainsi montré qu’avec l’emploi de l’intelligence artificielle, au-delà de la question du remix, le polytélisme et les processus d’éditorialisation (Vitali-Rosati 2018) à l’œuvre viennent véritablement diminuer l’autorité artistique traditionnelle.
D’un point de vue étymologique, la condition hyperconnectée désigne l’état de ce qui est au-delà, au-dessus de la connexion, qui signifie, quant à elle, l’acte de lier des choses entre elles. Il s’agit donc avant tout de l’expression d’une agentivité, de la cristallisation d’un raccord entre deux ou plusieurs « choses », lesquelles peuvent être des agents (humains ou non humains, c’est-à-dire des machines) ou des entités sans agentivité propre, comme des plateformes web. Dans son sens plus courant, le préfixe « hyper » désigne également un caractère excessif, et l’on pourrait alors dire que la condition hyperconnectée est une hyperagentivité, celle de joindre d’une façon dépassant les critères habituels des entités étant elles-mêmes en capacité d’agir.
Dans ce chapitre, je souhaiterais m’intéresser principalement à un type d’agent qui exemplifie de façon tout à fait singulière cette condition hyperconnectée contemporaine. Cet agent – l’intelligence artificielle – intervient aujourd’hui dans de nombreux médiums (musique, peinture, texte, mais aussi vidéo, installations…), chacun recouvrant bien entendu ses propres singularités. L’intelligence artificielle, il faut le noter, est un champ aujourd’hui majoritairement dominé par un type de technique appelé l’apprentissage automatique, technique relativement récente dont j’aborderai certaines des spécificités plus en aval du texte. Pour l’étude qui suit, je me limiterai à la question des productions textuelles, en me concentrant principalement sur celles issues d’un des plus grands viviers en la matière, le concours NaNoGenMo. Comme je le montrerai, ce dernier est en effet particulièrement intéressant en ce qu’il met l’accent sur les œuvres et non sur les programmes utilisés (Cook et Colton 2018). Pour comprendre pourquoi ce concours participe d’une condition hyperconnectée, il faut examiner de plus près la popularité du projet. Le NaNoGenMo – acronyme de « National Novel Generation Month » – est un concours en ligne sur la plateforme GitHub, créée par Darius Kazemi en 2013, et dont la consigne est de passer le mois de novembre à écrire du code qui générera un roman de plus de 50 000 mots.
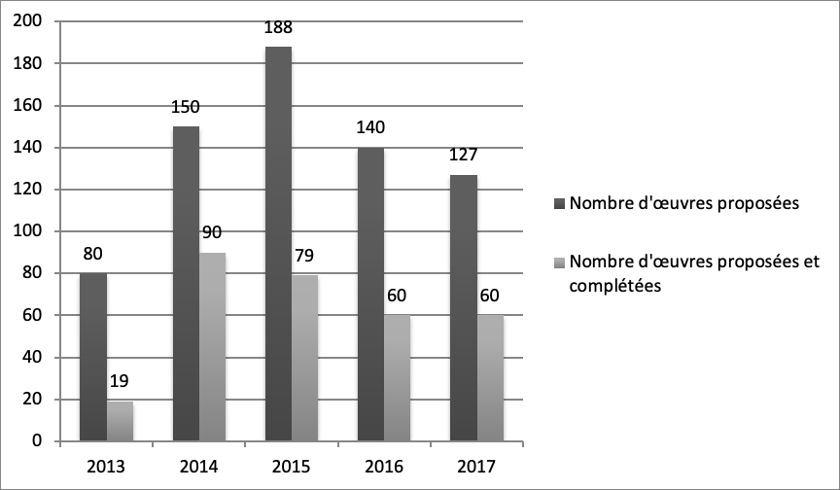
Bien que le pic de 188 œuvres proposées semble désigner l’année 2015 comme la plus fructueuse (diagramme disponible dans la version en ligne de l’ouvrage), c’est en fait l’année 2014 avec 90 projets complétés qui s’avère la plus intéressante. Les projets « complétés » (completed) sont en effet ceux qui remplissent les critères du concours, soit une œuvre générée de plus de 50 000 mots, et surtout la mise à disposition du code utilisé pour sa génération, ainsi que des données utilisées pour entraîner les algorithmes. En cinq années, la production de textes générés par du code représente donc 308 œuvres, soit un peu plus de la moitié de ce que représente une rentrée littéraire en FrancePour la rentrée 2018, 567 nouveaux romans auront ainsi été publiés (Sutton 2018).↩︎. Si d’autres sites spécialisés (Literai.com, 18 œuvres publiées dont 16 en 2016) et concours (Hoshi Shinichi Literary Award) adoptent la même démarche, des initiatives ponctuelles et isolées se saisissent d’œuvres de la culture populaire (Harry Potter, Game of Thrones) pour créer de potentielles suites, des chapitres, voire des œuvres entières dérivéesVoir « Harry Potter and the Portrait of What Looks Like a Large Pile of Ash », Botnik (s. d.), ainsi que Zack Thoutt, « Read The First Chapter of ‘The Winds of Winter,’ Written By a Neural Network » (2017).↩︎. En parallèle, le phénomène est de plus en plus publié en version papier : un recueil de poèmes générés par intelligence artificielle a récemment été publié par une maison d’édition majeure en Chine (The Sunlight that Lost the Glass Window, 2018), et une collection (Using Electricity, éditée par Nick MontfortLa collection Using Electricity est publiée par Counterpath Press.↩︎) lui est désormais également consacrée, laquelle reprend d’ailleurs de nombreux auteur.rice.s ayant présenté des textes lors des concours NaNoGenMo (notamment Li Zilles et Allison Parrish)Il est sans doute trop tôt pour proposer que le relatif essoufflement de la production sur des plateformes dédiées depuis deux ans soit corrélé d’une introduction dans la littérature papier, plus classique, mais le phénomène mérite d’être mentionné, qu’il se confirme ou non dans le futur.↩︎.
Ces textes s’inscrivent à mon sens dans la nouvelle vague de littérature médiatique, que René Audet et Simon Brousseau voient comme détachée de la fixité des contenus (Audet et Brousseau 2011). Cette forme de création déplace l’intérêt plus souvent qu’à son tour sur le processus de production plutôt que l’œuvre elle-même (Audet 2015). Pour Audet et Brousseau, la littérature médiatique, littérature de l’écran, se distingue entre autres par son accumulation archivistique, les auteurs allant jusqu’à qualifier les productions en question d’œuvres-archivesÀ ce titre, deux œuvres-archives sont notamment présentées : le site web de François Bon, Le Tiers-Livre, ainsi que Désordre.net de Philippe de Jonckheere.↩︎. Les œuvres générées par intelligence artificielle exemplifient particulièrement ce phénomène, non pas tant en raison d’une intention d’auteur.rice comme l’on pourrait le croire de prime abord, mais en raison de l’outil principal utilisé pour sa création. Cet outil implique une certaine confusion entre différents agents créatifs, ce qui rend délicat un examen esthétique cohérent des œuvres envisagées. Devant une telle problématique, mon hypothèse est qu’il importe de distinguer entre ces différents agents afin d’évaluer au mieux la réalité artistique des textes produits, ce que je me propose de faire dans ce chapitre.
Le polytélisme, ou la rencontre de différentes esthétiques au sein d’une même œuvre. De la génétique à l’esthétique
L’analyse esthétique de nombre d’œuvres numériques exige une recherche génétique, principalement en raison de l’importance du processus dans leur production (Audet 2015). En matière d’œuvres générées par intelligence artificielle, cette étude est complexifiée par l’autonomie apparente du processus de production amenée par les algorithmes actuels d’apprentissage automatique (Boden 2010). Cette autonomie relève d’une agentivité différente de celle de l’utilisateur.rice de l’algorithme, soit l’artiste ou l’auteur.rice selon le sens commun. L’autonomie de l’algorithme participe également d’un certain agir en condition hyperconnectée, en ce sens qu’elle dispose de ses propres contraintes et de ses propres objectifs qui, s’ils sont éventuellement modifiables par le biais du code, ont pourtant leurs zones d’ombre (Léon et Gervàs 2010). Afin de faire comprendre les tenants et aboutissants de ma réflexion, je vais tenter d’expliquer au moins de façon liminaire le fonctionnement de la génération computationnelle telle qu’elle m’intéresse ici.
La définition que je souhaiterais adopter est celle proposée par Margaret A. Boden, selon laquelle il y a génération computationnelle d’art (computer-generated art) lorsque l’œuvre résulte de l’action d’un programme informatique qu’on laisserait fonctionner seul, avec une interférence minimale ou nulle d’un être humain (Boden 2010, 141). Dans cette condition, le programme (en l’occurrence, l’IA) est un agent créatif autonome dont il convient de déterminer l’influence. À l’heure actuelle, je voudrais me concentrer sur les productions textuelles issues d’apprentissage automatique (machine learning), soit la technique la plus actuellement favorisée par la recherche (Bostrom 2014). Cette technique peut être divisée en trois types différents : l’apprentissage supervisé, l’apprentissage non supervisé et l’apprentissage par renforcement. Dans ce chapitre, je m’intéresserai uniquement au deuxième type, soit l’apprentissage non supervisé, ce dernier étant celui qui pose le plus d’interrogations du point de vue de l’autonomie de la création. Cette technique peut être définie comme suit :
Dans l’apprentissage non supervisé, l’apprentissage est motivé par le principe selon lequel les caractéristiques cooccurrentes engendrent des attentes qu’elles coexisteront à l’avenir. L’apprentissage non supervisé peut être utilisé pour découvrir des connaissances. Les programmeur.se.s n’ont pas besoin de savoir quels modèles/clusters existent dans les données : le système les trouve par lui-même (ma traduction, Boden 2016, 47).
Pour les créations textuelles qui feraient usage d’apprentissage automatique non supervisé, l’auteur.rice ne travaille donc plus nécessairement sur la planification de la structure, sur celle de la forme comme l’ont fait par le passé certain.e.s auteur.rice.s comme Jean-Pierre Balpe avec ses fameux « moules » ou canevas (Balpe 1987) : c’est l’intelligence artificielle qui accomplira seule ce travail. L’algorithme créera donc de façon autonome l’œuvre générée, justement en fonction des corrélations trouvées par apprentissage au sein des données sur lesquelles il aura été entraîné. Pour être plus précis, l’algorithme interviendra à la fois sur le plan sémantique (puisqu’il remaniera le contenu des données textuelles utilisées) et sur le plan de l’organisation structurelle du discours (puisqu’il en aura préalablement fait l’analyse). Cette autonomie sera ensuite appuyée ou non lors de la période suivant la génération, puisque certain.e.s auteur.rice.s ne toucheront pas au texte produit tandis que d’autres utiliseront, au contraire, les algorithmes comme un modèle d’écriture, une base sur laquelle retravailler. C’est ainsi que fonctionne l’artiste Jhave, dont les poèmes générés sont ensuite édités par ses soins, l’intelligence artificielle apparaissant davantage comme un partenaire que comme un outil, dans un phénomène d’inversion par rapport à d’autres œuvres : l’intelligence artificielle fournit le cadre (le champ sémantique, la structure), l’auteur travaillant au contraire le style et la diégèse, afin que l’œuvre produite fasse sens. Il y aura donc, la plupart du temps, une autonomie de l’acte d’organisation structurelle du discours et une autonomie de l’acte de production sémantique, qui s’appuie également sur la syntaxe. L’œuvre créée bénéficiera ainsi d’une autonomie poétique par rapport à son auteur.rice, qui opère donc à la fois sur l’axe syntagmatique et sur l’axe paradigmatique.
En tant que tels, les algorithmes d’apprentissage automatique ont pour fonctionnement d’encoder l’esthétique des données sur lesquelles ils ont été entraînés (McCormack et al. 2014; Sobel 2017). Ce phénomène a plusieurs conséquences. La première, et la plus évidente, est que l’on retrouve dans l’œuvre générée une part (plus ou moins grande, selon les paramètres de création de l’œuvre) de l’esthétique des données utilisées pour la génération. Le terme de « données » peut bien sûr désigner des films, des textes, des peintures ou de la musique : tant que ces données sont traitées par l’algorithme, elles pourront faire l’objet d’une appropriation de leurs caractères distinctifs (Lebrun 2018). L’encodage de l’esthétique produit par les algorithmes représente une moyenne statistique desdites données. Un tel fonctionnement technologique a, en matière de texte, pour conséquence première de créer un rapport intertextuel également statistique entre le texte généré et les données précitées. Ce singulier rapport intertextuel, ce lien entre deux textes ou entre deux œuvres éventuellement, n’existerait pas sans les techniques contemporaines d’apprentissage automatique ; il cristallise admirablement à mon sens la condition hyperconnectée dans laquelle s’inscrit ce type de production artistique.
Un tel rapport implique en effet que l’œuvre générée soit en partie composée de l’esthétique des données sur lesquelles l’auteur.rice a choisi d’entraîner ses algorithmes. Ces données (bien souvent des œuvres, en l’occurrence) sont également issues des choix de leurs propres auteur.rice.s. En s’inscrivant dans une nouvelle catégorie de l’art du remix, les auteur.rice.s d’œuvres générées par intelligence artificielle ont en effet tendance à utiliser des œuvres reconnaissables, et donc relevant d’une certaine célébrité (Cook et Colton 2018). À ce sujet, Mako Hill et Monroy-Hernández ont établi que cette utilisation d’œuvres populaires permettait aux auteur.rice.s du remix de chercher une certaine « résonance culturelle » (cultural resonance) pour leurs travaux, et que cela nécessitait de facto de maintenir dans le remix un certain degré de reconnaissance avec l’original (Hill et Monroy-Hernández 2013). Cette assertion n’est bien sûr pas absolue, et certain.e.s auteur.rice.s préféreront au contraire utiliser des œuvres ne faisant pas l’objet d’une grande reconnaissance institutionnelle, critique ou populaire, leur choix se positionnant alors sur le critère de l’utilité de l’œuvre par rapport aux objectifs qu’ils et elles se sont fixés.
Il n’empêche, les œuvres appropriées sont donc également le fruit d’une agentivité, celle de leurs propres auteur.rice.s : ils constituent de fait un deuxième type d’agent en matière de textes générés par intelligence artificielle. Ce phénomène était bien sûr déjà présent dans le remix, mais il est ici rendu singulier par la capture de l’esthétique que fournissent les algorithmes d’apprentissage automatique non supervisé. Ce lien entre la ou les données ou œuvres appropriées et l’œuvre générée est à mon sens inédit dans l’histoire de la création artistique : il permet de déplacer une esthétique pas nécessairement numérique et pas nécessairement contemporaine (quid d’algorithmes entraînés sur l’Ancien TestamentVoir The Book of Eliza (Borenstein 2015).↩︎ ?), vers une œuvre qui est par contre de façon structurelle numérique et contemporaine. Il en résulte forcément que la condition classique du pacte de lecture entre un.e auteur.rice et son ou sa lecteur.rice est dépassée. Un nouveau pacte est ainsi créé, lequel implique trois agents créatifs (auteur.rice, algorithme et œuvres appropriées) que le ou la lecteur.rice devra considérer s’il ou elle souhaite comprendre l’esthétique de l’œuvre générée.
Car le troisième agent créatif de l’œuvre générée par intelligence artificielle, c’est bien sûr l’auteur.rice, soit la personne qui a – pour reprendre une définition juridique – « mis en place les arrangements nécessaires à la création de l’œuvreLe terme est issu du Design and Copyright Act britannique de 1988, dont de nombreuses législations s’inspirent à l’heure actuelle concernant la question de la titularité des œuvres générées par des machines (Cruquenaire et al. 2017).↩︎ ». Il ou elle agit dans la création à plusieurs titres. D’abord, il ou elle sélectionne les textes sur lesquels son système d’intelligence artificielle sera entraîné, gardant généralement en tête le principe selon lequel la plus grande quantité de données (donc le plus souvent de texteL’utilisation de données textuelles peut également être enrichie par des données non-textuelles, comme des données GPS par exemple (Goodwin 2017).↩︎) donnera de meilleurs résultats. Il ou elle détermine ensuite le type d’algorithmes qui sera utilisé, en l’occurrence souvent un type issu de la classe « connexionniste », selon la typologie établie par Pedro Domingos (2015). Les algorithmes en question sont aussi divers que variés, mais l’un des plus utilisés à l’heure actuelle est celui dit du LSTM (Long Short-term Memory), partie intégrante des RNN (Recurrent Neural Network) qui miment la structure des neurones humains en les répliquant de manière artificielle. En piochant au sein de différentes bibliothèques logicielles – GitHub étant le service open source le plus actuellement utilisé – l’auteur.rice constituera son propre code (ou utilisera un système déjà mis en place) afin de l’entraîner sur les données choisies au départ. Une fois l’entraînement de l’algorithme effectué (un procédé qui peut être plus ou moins long, en fonction de la taille des données utilisées et de la puissance de calcul des cartes graphiques sollicitées) et certains paramètres réglés, l’auteur.rice pourra générer du texte de façon quasi illimitéeSuivant les règles de pseudo-hasard (pseudorandomness) établies notamment par John Von Neumann, la génération n’est pas infinie ni parfaitement aléatoire sur le plan mathématique. Elle est par contre tellement élevée qu’elle en a l’apparence. On retrouvait déjà la même idée pour l’œuvre de Queneau, Cent mille milliards de poèmes (1985), qu’il serait vain de vouloir tout parcourir : l’intérêt, déjà là, est déplacé du texte vers le processus.↩︎, ledit texte exprimant l’esthétique des données appropriées, sans qu’il y ait toutefois de cohérence sur le plan diégétiqueÀ moins que la génération du texte, en plus d’être faite à partir d’algorithmes d’intelligence artificielle, utilise également le principe du « moule » tel qu’il a été mis en place notamment par Jean-Pierre Balpe dans les années 90. Ce moule est en réalité une sorte de canevas qui permet de générer du texte selon une cohérence syntaxique préétablie. Le travail sur la contrainte de ce canevas rapproche sans doute bien plus cette méthode (qualifiée de génération automatique) de l’OuLiPo que la génération de textes par intelligence artificielle.↩︎. Par la suite, l’auteur.rice pourra soit disposer directement du texte (et, par exemple, le rendre disponible sur GitHub), soit le « re »-travailler. Ce point est à mon sens particulièrement intéressant au titre de cette étude, parce que le travail d’auteur.rice tel qu’on l’entend habituellement est alors déplacé vers un travail de réécriture, et non de production première du texteVoir l’article « Pour une typologie des œuvres littéraires générées par intelligence artificielle » (Lebrun 2020).↩︎. Comme exprimé à propos de la curation dans le chapitre « La collection algorithmique de fragments photographiques comme technologie mémorielle » dans cet ouvrage, les décisions algorithmiques reconditionnent le rôle des actants de l’art numérique ; en matière de littérature générée, la figure de l’écrivain.e disparaît, ou plutôt elle est déplacée vers les œuvres choisies par l’auteur.rice, ce.tte dernier.ère endossant un rôle nouveau et singulier.
La pluralité des agents créatifs, ou la nécessité d’un concept pour l’analyse d’un phénomène distinct au sein de la culture du remix
Face à ce type inédit d’œuvre numérique et à la pluralité des agents créatifs qui la composent, la création d’un cadre théorique semble une nécessité. Le phénomène se distingue en effet des rapports classiques de production collaborative, par exemple entre un auteur.rice et un éditeur.rice. Dans une telle relation de création, l’auteur.rice aura ses propres objectifs (lesquels peuvent être le dévoilement, la littérarité ou l’extranéité, pour ne reprendre que certains des termes de l’analyse formaliste, à moins que ce ne soit tout simplement de raconter une bonne histoire) tandis que l’éditeur.rice, en plus d’accompagner dans certains cas l’auteur.rice dans sa démarche, aura également à prendre en compte la correspondance de l’œuvre à un ensemble plus grand (une collection donnée, par exemple, ou un public cible). Il en va différemment pour les œuvres générées par intelligence artificielle. En effet, comme la matière première de la création est un ensemble de données sur lequel les algorithmes vont extraire une moyenne statistique et esthétique, ce rapport est a priori dénué d’une intention artistique (mais pas d’agentivité, comme je l’ai vu précédemment) : il est la production d’une moyenne esthétique sur un ensemble d’intentions éventuellement artistiques (les fameuses données appropriées).
On en retrouve nécessairement la trace dans l’œuvre générée comme dans tout phénomène de remix, sauf que la nécessité technique d’un grand nombre de données pousse les auteur.rice.s d’œuvres générées par intelligence artificielle à favoriser les grands corpus. L’œuvre dérivée n’est donc plus fondée sur « une » œuvre primaire reconnaissable comme dans l’analyse de Mako Hill et Monroy-Hernández, mais sur un style, sur une identité – cette dernière étant forcément basée sur une production importante sur le plan quantitatif. À titre d’exemple, la plupart des tutoriels existants concernant la génération de textes recommandent d’entraîner les algorithmes sur des fichiers de textes entre 3 Mo et 10 Mo, les meilleurs résultats provenant des entraînements effectués sur des fichiers approchant les 100 MoÀ titre indicatif, la totalité de La Recherche du temps perdu de Marcel Proust représente 3 Mo.↩︎. Cette exigence technique rend difficile d’envisager des générations de textes basées sur une seule œuvre : hormis les épiphénomènes d’auteur.rice.s prolifiques et réputé.e.s comme tels (Proust, Balzac, Trollope), les fichiers de texte croisant plusieurs auteur.rice.s, plusieurs ouvrages ou plusieurs époques sont donc monnaie courante, à tel point qu’il serait laborieux de tenter de les citer (je me contenterai de pointer notamment Parrish 2018; Laüfer 2018; Johnston 2018 pour des publications papier).
Une analyse esthétique des œuvres générées ne peut, bien sûr, faire l’impasse sur cette réalité. Pour autant, le cadre génétique actuel ne permet pas d’appréhender ce phénomène autrement que sous l’angle déjà bien établi du remix, lequel ne s’accorde pas exactement avec la question des œuvres générées par IA. Défini par Eduardo Navas (2012), le remix est l’activité par laquelle on prélève des échantillons de matériaux préexistants afin de les combiner en de nouvelles formes en fonction de ses goûts personnels – or l’intelligence artificielle ne prélève pas d’échantillons, mais travaille sur l’ensemble des données fournies. La combinaison qui en résulte, encore une fois, n’est pas faite en fonction de goûts personnels, mais de la moyenne esthétique desdites données. Ce n’est donc pas le choix de l’auteur.rice qui crée l’œuvre, c’est le choix de l’algorithme. Bien sûr, c’est l’auteur.rice qui choisira quels algorithmes utiliser (ainsi que leurs paramètres), mais la distinction avec le remix se situe en ce point que ce n’est pas l’artiste, mais l’algorithme qui prélève ce qui importe, quand bien même le résultat pourra être réécrit et édité par l’auteur.rice par la suiteUne reconnaissance de l’œuvre sous l’angle du mashup pourrait être plus pertinente car bien que le mashup soit défini par l’utilisation d’une technologie forcément web (Robertson 2014), de plus en plus de navigateurs proposent des fonctionnalités d’apprentissage machine (voir Carter et Smilkov, s. d.). Il faudrait cependant étendre la définition du mashup – ce qui pourrait être l’objet d’un travail ultérieur – et tenir compte du fait que le mashup est essentiellement combinatoire, et ne fournit donc pas d’analyse des données faisant l’objet d’une réutilisation.↩︎. Les algorithmes d’intelligence artificielle sont donc des purs agents de la condition hyperconnectée : ils appellent ainsi à mon sens un renouvellement de la terminologie désignant les œuvres numériques en faisant usage. Il me semble en effet raisonnable de considérer les algorithmes d’apprentissage automatique comme des actants de la création à part entière. Le résultat de leur utilisation n’est pas prévisible au même titre qu’un outil comme le pinceau ou le traitement de texte, puisqu’ils décèlent des corrélations et extraient de la valeur des données de façon singulière, sans qu’il soit possible de le mesurer a priori. L’utilisateur.rice d’apprentissage automatique saura qu’il capte quelque chose de l’identité des données (Benjamin Sobel parle à ce titre de « personnalité », voir Sobel 2017), mais l’outil agit d’une façon autonome lorsqu’il est entraîné Veale et Cardoso (2019). Face à la pluralité des intentions esthétiques pouvant se retrouver au cœur d’une œuvre créée par intelligence artificielle, je proposerai de qualifier ce phénomène de polytélisme dans la suite de ce chapitre, un terme à mon sens utile pour désigner la rencontre d’agents humains et non humains dans une même production esthétique. À l’inverse de l’autotélisme (qui n’a d’autre but que soi-même), le polytélisme (du grec πολλοί, « plusieurs », et τέλος, « le but ») appelle la réunion de plusieurs intentions d’auteur.rice.s au sein de la même œuvre, sans pour autant être collaborative ni déterminée par les goûts d’un.e auteur.rice. Le polytélisme se distingue donc de l’assertion de Marcel Duchamp selon laquelle toute forme d’art a une multiplicité d’auteur.rice.s, puisque ce n’est pas tant la diversité de ces dernier.ère.s qui compte que la rencontre au sein d’un même produit culturel de plusieurs intentions esthétiques singulières qui ne travaillent pas nécessairement dans le même but, et dont la plus grande partie est déterminée par un agent non humain. En quoi ce polytélisme influence également la posture des auteur.rice.s d’œuvres générées par intelligence artificielle, c’est ce que je vais maintenant essayer d’expliquer.
Les conséquences du polytélisme sur la posture d’auteur.rice : une dilution de l’éthos
La première conséquence de l’utilisation d’intelligence artificielle dans la création semble être un délaissement de l’éthos d’écrivain.e dans le travail de production. Cette notion d’éthos, développée par Aristote, est reprise depuis quelques années pour l’analyse des relations sur internet (Couleau et al. 2016; Coutant et Stenger 2013; Folk et Apostel 2013; Frobish 2012; Georges 2009) – elle s’envisage donc au regard des spécificités du discours en ligne, comme la présence d’avatars par exemple, ou encore la simultanéité des échanges. Surtout, l’éthos doit être vu comme une expérience commune, qui se co-construit ; c’est déjà, en somme, une forme de connexion :
Étudier l’éthos, c’est s’appuyer sur une réalité simple, intuitive, celle d’un phénomène qui est coextensif à tout emploi de la langue : le destinataire construit nécessairement une représentation du locuteur à travers ce que ce dernier dit et sa manière de le dire (Maingueneau 2014, 46).
Or si le texte généré par intelligence artificielle se présente de plus en plus comme de la littérature (c’est ce qu’indique, à tout le moins, l’introduction de textes issus de l’écran vers une publication papier), l’auteur.rice, bien souvent, ne s’embarrasse pourtant pas d’une posture d’écrivain.e. Cette dernière, « historiquement construite et référée à l’ensemble des positions du champ littéraire » (Meizoz 2009), faite de topoï classiques de l’image collective et cristallisée par une « scénographie auctoriale » (Maingueneau 2013), en dépit (qui plus est !) du capital symbolique qu’elle recouvre, n’est absolument pas convoitée par les auteur.rice.s de textes générés par intelligence artificielle. Pourquoi ?
La raison la plus évidente est que les textes produits, sauf lorsqu’ils sont considérablement édités, n’ont pas de sens sur le plan diégétique. S’ils ont le mérite d’être produits par des algorithmes, la conséquence directe en est, en effet, l’incohérence narrative. Pourquoi alors un.e auteur.rice aurait à porter la responsabilité de l’échec littéraire, c’est-à-dire diégétique, du texte fourni ? Ainsi, il semble que le polytélisme partage les torts : si l’œuvre d’art est mauvaise, c’est beaucoup de la faute de l’algorithme, un peu de la faute des données et finalement peu de la faute du ou de la programmeur.se. Une condition somme toute normale au vu de l’état actuel des technologies de Traitement Automatique du Langage, encore largement sujet à améliorations (Hirschberg et Manning 2015; Bostrom 2014)Le terme de TALN (Traitement automatique du langage naturel) est une traduction directe de l’appellation Natural Language Processing (NLP).↩︎. Il en découle que l’auteur.rice a ainsi de nombreux avantages sans réellement d’inconvénients. Il ou elle est toujours reconnu.e par la communauté comme la personne par laquelle l’œuvre advient, au même titre que pour les créations collaboratives entre artistes et programmeur.se.s, où c’est souvent l’artiste et non le ou la technicien.ne qui bénéficiera du capital symbolique, quand bien même l’œuvre aura été le fruit d’efforts partagés (Fourmentraux 2006). De manière fascinante, l’autonomie de l’outil conduit même parfois les auteur.rice.s à personnifier les IA qu’ils utilisent, et à leur reconnaître conséquemment une agentivité sans doute plus importante qu’elle ne l’est en réalitéCe point sert d’ailleurs mon propos précédent, sur l’agentivité reconnue des algorithmes d’apprentissage machine.↩︎.

Cette posture tout à fait particulière les place souvent dans un rôle plus proche de l’éditeur.rice que de l’écrivain.e, le rapport à l’œuvre générée étant alors le même que pour une œuvre de commandeCertains juristes recommandent d’ailleurs à titre de placer les œuvres générées par intelligence artificielle sous le régime du « work made for hire ». L’idée est que le droit crée une situation qui n’existe pas en tant que telle, comme elle le fait déjà avec l’adoption : c’est ce qu’on appelle une fiction juridique. Dans ce cas, les auteurs proposent que soit reconnue la conclusion d’un contrat entre l’auteur et les algorithmes utilisés, selon le principe de la commande en droit américain. L’auteur posséderait ainsi les droits sur l’œuvre générée (Yanisky-Ravid 2017; Bridy 2012).↩︎.
Cette analyse, qui est à mon sens valable pour la majorité des productions à l’heure actuelle, doit cependant être circonscrite aux concours et aux plateformes issues d’une communauté de créativité computationnelle, où la majorité des individus ne se définissent pas comme des artistes, mais comme des programmeur.se.s dont les motivations sont essentiellement le développement d’outils à potentiel économique (Cook et Colton 2018). Il en va bien entendu différemment des utilisateur.rice.s d’intelligence artificielle revendiquant une posture d’artiste, davantage représentés par les publications papier (ne serait-ce que parce qu’elles nécessitent un investissement, et donc une certaine stratégie éditoriale). Dans la suite de ce chapitre, j’aimerais m’intéresser de façon plus approfondie à cette communauté, et à la manière dont celle-ci participe au phénomène d’éditorialisation des œuvres générées.
Une condition hyperconnectée favorisant l’éditorialisation du code
Comme l’écriture par blogue, « faiblement contractualisée et possédant sa sphère référentielle propre » (Gefen 2010), la littérature produite par intelligence artificielle se construit au sein d’une communauté, celle de la recherche en créativité computationnelle, souvent décrite comme singulière et difficile d’accès (Cook et Colton 2018). Beaucoup d’auteur.rice.s majeur.e.s ont écrit sur l’intérêt que portent les communautés de programmeur.se.s aux enjeux de la culture libre (Lessig 2008; Benkler 2009), et je me passerai donc d’approfondir ce propos pour m’intéresser plutôt à ses conséquences en matière de création numérique. Il est logique que ce contexte de culture libre, appuyé par une communauté aux liens serrés et aux enjeux partagés, offre un terreau favorable à l’éditorialisation des œuvres, soit le phénomène par lequel toute production présente sur les réseaux informatiques (web, internet, protocoles divers) peut faire l’objet d’un processus d’édition constante. Le terme d’éditorialisation, en partie développé par Marcello Vitali-Rosati (2018), sert donc à qualifier des contenus qui, par leur disponibilité et la possibilité de modification présente sur les réseaux, ne sont jamais finis et rendent de fait difficile leur étude (quelle version du texte, du blogue, du site analyser ? Pour quelles raisons ?). L’œuvre est alors avant tout qualifiée, par le mouvement qui l’engendre, de phénomène propre à la culture de l’écran (Audet et Brousseau 2011). Deux points me semblent fondamentaux à cet égard. D’abord, cette éditorialisation est essentiellement collective. Ensuite, elle est avant tout celle du code et non du texte généré, qui n’en est que la conséquence.
Quelques exemples permettront d’asseoir facilement mon propos. L’œuvre Generated Detective (Borenstein 2014) fait par exemple l’objet de 62 commentaires, lesquels participent de l’éditorialisation collective de l’œuvre, dont pas moins de huit versions seront proposées au cours du mois de novembre 2014.
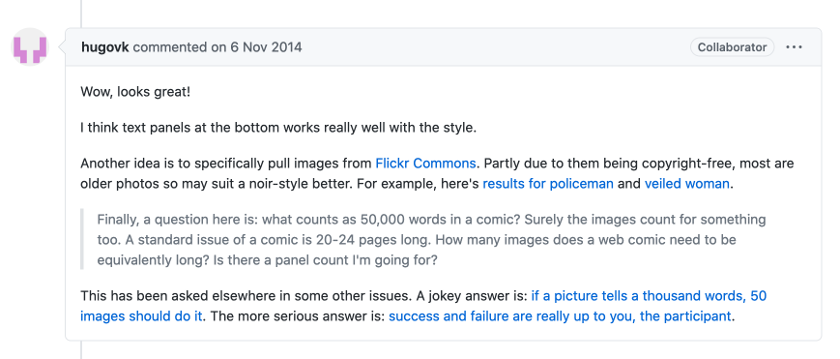
Un participant régulier du concours nommé Hugo VK propose notamment de préférer l’utilisation de photographies présentes sur la plateforme Flickr commons, laquelle semble plus adaptée aux objectifs de Greg Borenstein, une proposition dont il tient compte dans la génération suivante.
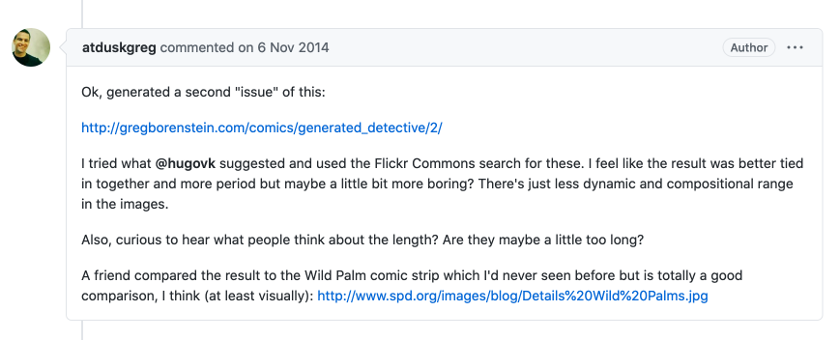
De la même manière, le fondateur de NaNoGenMo Darius Kazemi suggère ensuite de générer l’œuvre en se fondant sur la structure d’une page de comics, et non sur le modèle de la case de bande dessinée, idée dont tiendra également compte Borenstein.
L’œuvre se distingue alors comme une œuvre-archive d’un type tout à fait singulier puisqu’elle conserve tant la marque des interventions extérieures dans son code que dans son rendu final, s’inscrivant dans cette littérature de l’écran décrite précédemment. Son rapport à la temporalité et à l’espace interroge également en ce qu’elle utilise comme matière des données (photographiques, mais aussi textuelles) extérieures à elle-même. Ces textes sont ainsi sollicités sous une forme certes primaire (car à l’interventionnisme limité) avant d’être appropriés pour en faire œuvre utile, provoquant un amalgame de différentes lignes temporelles ainsi que de différents espaces, dans une dimension syncrétique tout à fait unique.
Autre exemple, dans Twenty Seconds Summary d’Andrew Zyabin, le même Hugo VK propose d’utiliser deux nouveaux systèmes de grammaire (tracery.io et inflect.py) afin de remplacer les articles indéfinis « a » par des « an » dans le but d’améliorer la lisibilité, proposition dont Zyabin tiendra compte dans une version ultérieure.
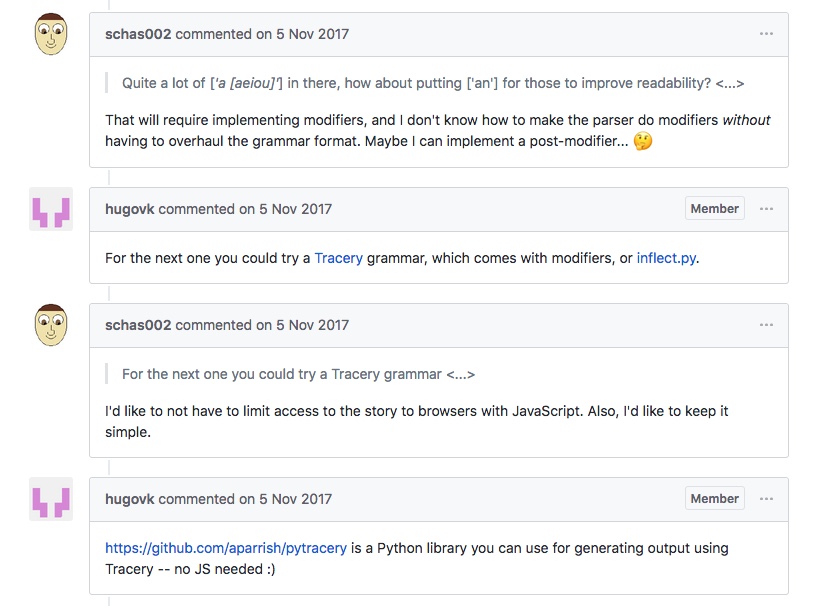
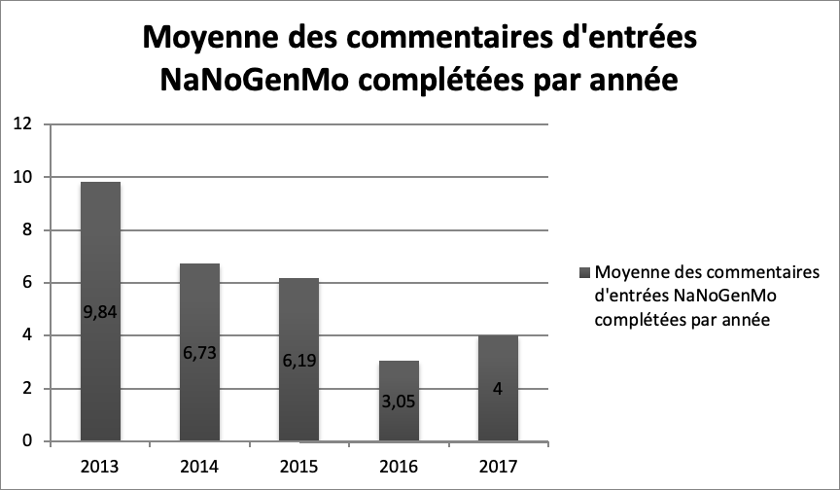
Ces deux exemples, pour éclairants et significatifs, sont toutefois loin d’être majoritaires. En effet, beaucoup de générations de textes ne débouchent pas sur des efforts d’éditorialisation, ne serait-ce qu’en raison du caractère circonscrit dans le temps du concours (le mois de novembre de chaque année) et de l’aspect informel et sans rétribution de celui-ci. Dans le graphique suivant (disponible dans la version en ligne de l’ouvrage), on voit ainsi que la moyenne du nombre de commentaires a baissé presque constamment depuis la création du concours en 2013, jusqu’à atteindre une moyenne de quatre commentaires par œuvre pour l’année 2017. Sans confondre corrélation et causalité, cette baisse des interactions est au moins indicative à mon sens d’une éditorialisation mesurée des œuvres produites sur NaNoGenMo.
Malgré cela, il me semble que l’on peut continuer à considérer que ce type de production s’inscrit dans la dynamique d’un « art de la communication » tel que décrit par Joanne Lalonde dans son ouvrage Le performatif du Web (Lalonde 2010, 7), comme le cite Gina Cortopassi dans son article. Tel que le mentionne fort à propos cette dernière, « [l]a présence et les actions des participant.e.s deviennent [en raison de cette dimension performative et communicationnelle] coextensives au temps de l’œuvre et de sa représentation ». Autre point important à mesurer au regard de l’éditorialisation, l’œuvre générée par intelligence artificielle n’est par définition jamais finie, non tant en raison de sa présence sur les réseaux qu’en fonction de son processus même de production. Une fois l’entraînement sur les données effectué, on sait en effet que la génération est virtuellement illimitée – elle peut être de 1000, de 100 000 ou de plusieurs millions de mots, même s’il est vrai que les générations les plus courtes sont souvent les plus pertinentes. Il est aussi intéressant de noter que les règles mises en place dans les communautés de génération textuelle appuient également un objectif de collaboration, que ce soit pour le concours NaNoGenMo ou la plateforme Literai.com : ces dernières forcent ou incitent très fortement les auteur.rice.s à partager tant l’œuvre que le code et les données sur lesquelles le système aura été entraîné. En mettant à disposition de tout un chacun le modèle algorithmique, n’importe qui peut générer un texte qui relève de la même essence que l’œuvre générée avant toute édition, un facteur d’éditorialisation important à mon sens. On retrouve en filigrane de ces règles le polytélisme que j’ai décrit plus tôt : en reconnaissant le caractère tripartite de toute génération textuelle et en fournissant aux autres membres de la communauté ces éléments, ces concours et plateformes valident la reconnaissance des diverses influences esthétiques sur l’œuvre générée, et en forment l’archive – l’œuvre-archive prenant alors un tout nouveau sens, celui d’un rapport intertextuel avec les œuvres ayant servi à l’entraînement. Ces règles sont également la preuve que l’acte de création des œuvres créées par intelligence artificielle s’inscrit dans une condition hyperconnectée singulière, fondée sur l’idéal de culture libre mentionné plus tôt, et participant d’un éthos qui déroge au régime habituel de l’autorité artistique.
Références
Accéder à cette bibliographie sur Zotero
Contenus additionnels
Présentation du concours NaNoGenMo (National Novel Generation Month) sur GitHub
Crédits : Darius Kazemi
Proposé par editeur le 2020-09-22
Plateforme Literai - Fiction Written by Computers
Literai a été créé en 2016 par Myles O’Neill, Anthony Voutas, Isadora Lamego et Annette Zou.
Crédits : Literai.com
Proposé par editeur le 2020-09-22
Tom Lebrun
Tom Lebrun est juriste, spécialisé en droit du numérique et en droit d’auteur. Étudiant au doctorat en littérature à l’Université Laval, il travaille actuellement sur la question de la génération de textes par intelligence artificielle. Il publie régulièrement sur les questions de droit d’auteur, de culture numérique et de rapport entre droit et intelligence artificielle. Ses recherches sont financées par le Fonds de recherche du Québec – société et culture (FRQSC).